Optimizing Retrieval-Augmented Generation (RAG) for Legal Data Pipelines
Optimize Retrieval-Augmented Generation (RAG) for legal data pipelines to boost accuracy, protect confidentiality, and enhance efficiency in your law firm.

If you’re a lawyer or part of a law firm, you’ve probably noticed how artificial intelligence is cropping up in nearly every corner of the legal industry. Whether it’s helping with document review or offering quick summaries of case law, AI promises to streamline repetitive tasks and free you up for more strategic work. One of the more exciting developments is Retrieval-Augmented Generation (RAG), which combines the efficiency of AI-driven language models with the reliability of curated knowledge bases or databases.
Still, if you’ve heard about RAG, you might have questions about how it fits into legal data pipelines—after all, law is a high-stakes field and you have zero room for slip-ups. Below are a few must-know insights on optimizing RAG in a legal context, so you can move forward with greater confidence.
RAG Isn’t Just “Hype”—It’s a Practical Tool
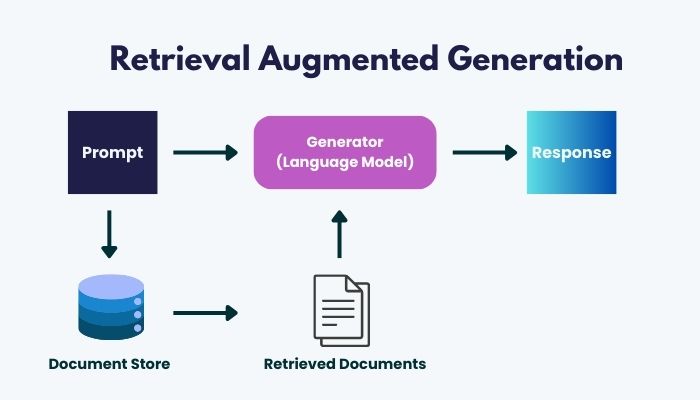
RAG might sound like a buzzword, but at its core, it’s a pretty straightforward concept. Think of it as a way to ensure AI-generated text is based on solid references rather than on guesswork. When you ask a question in a text generation system enhanced by RAG, the system doesn’t just rely on its training. It also retrieves relevant documents—in your case, possibly a library of statutes, case law, or firm-specific precedents—and uses that information to craft a more accurate response.
Why it matters for lawyers: By tethering your AI to verified legal sources, you lower the risk of inaccurate or incomplete answers.
Quality Data Inputs Are the Backbone of a Reliable RAG Pipeline
A fancy AI model isn’t magic on its own. It needs high-quality, up-to-date legal data to produce results you can trust. Many law firms keep troves of documents—case summaries, briefs, memos—but not all collections are neatly formatted or consistently labeled. RAG systems work best when the source data is well organized.
Why it matters for lawyers: Gaps or inconsistencies in data can lead to flawed legal insights. Ensuring your documents are properly indexed, named, and version-controlled sets the stage for the AI to deliver reliable answers.
Balancing Confidentiality With Functionality
Legal data often includes sensitive client information and privileged communications. Naturally, you’ll be wary about how an AI system handles it all. The good news is you can implement RAG in a way that respects confidentiality. Some firms set up private or on-premises servers, and they carefully restrict data access—so only the right people and the AI system can view secure client documents.
Why it matters for lawyers: Unlike a general AI chatbot, a well-designed RAG pipeline for legal teams can function entirely in-house. That means your private archives stay under your control, reducing compliance worries.
Customization Is Key
Not all law firms have the same priorities. For instance, a personal injury firm might rely heavily on medical reports and insurance regulations, while a corporate law firm might handle securities filings. Your RAG pipeline should mirror your practice areas, pulling data from specific sources that actually matter to your clients. Tailoring the retrieval segment makes your AI tool more about quick, relevant insights rather than random, broad-brush answers.
Why it matters for lawyers: Customizing the pipeline ensures the AI is referencing the right body of law, saving you time and boosting the accuracy of your search results.
A Well-Crafted Review Process Solidifies Trust
No matter how sophisticated AI becomes, human oversight is still crucial—especially in the legal world. When a RAG tool produces a draft memo or research findings, there should be a review stage where a lawyer double-checks the material. This feedback loop makes it easier to refine the system over time, flag inaccuracies, and continuously improve the data retrieval process.
Why it matters for lawyers: Ultimately, you’re the expert. A well-structured feedback mechanism helps the AI learn from any mistakes, leading to even more reliable outputs in the future.
Moving Forward With Confidence
If you’re considering weaving RAG into your firm’s data pipeline, remember that it’s not an all-or-nothing approach. Start with smaller tasks—like summarizing routine documents or searching for relevant case law—to get a sense of how well it fits your needs. From there, you can scale up to more complex projects.
By striking the right balance between technological innovation and the careful stewardship of sensitive data, your legal team can boost efficiency without compromising accuracy. At the end of the day, RAG is a tool, and like any tool, its effectiveness depends on how thoughtfully you put it to work. And in the high-stakes world of law, that extra bit of confidence can make all the difference.



Put a legal AI workflow to work — the right way.
Talk through the workflow you want to automate — contract review, drafting, or document intelligence — with a team that ships secure AI for law firms.